Overview
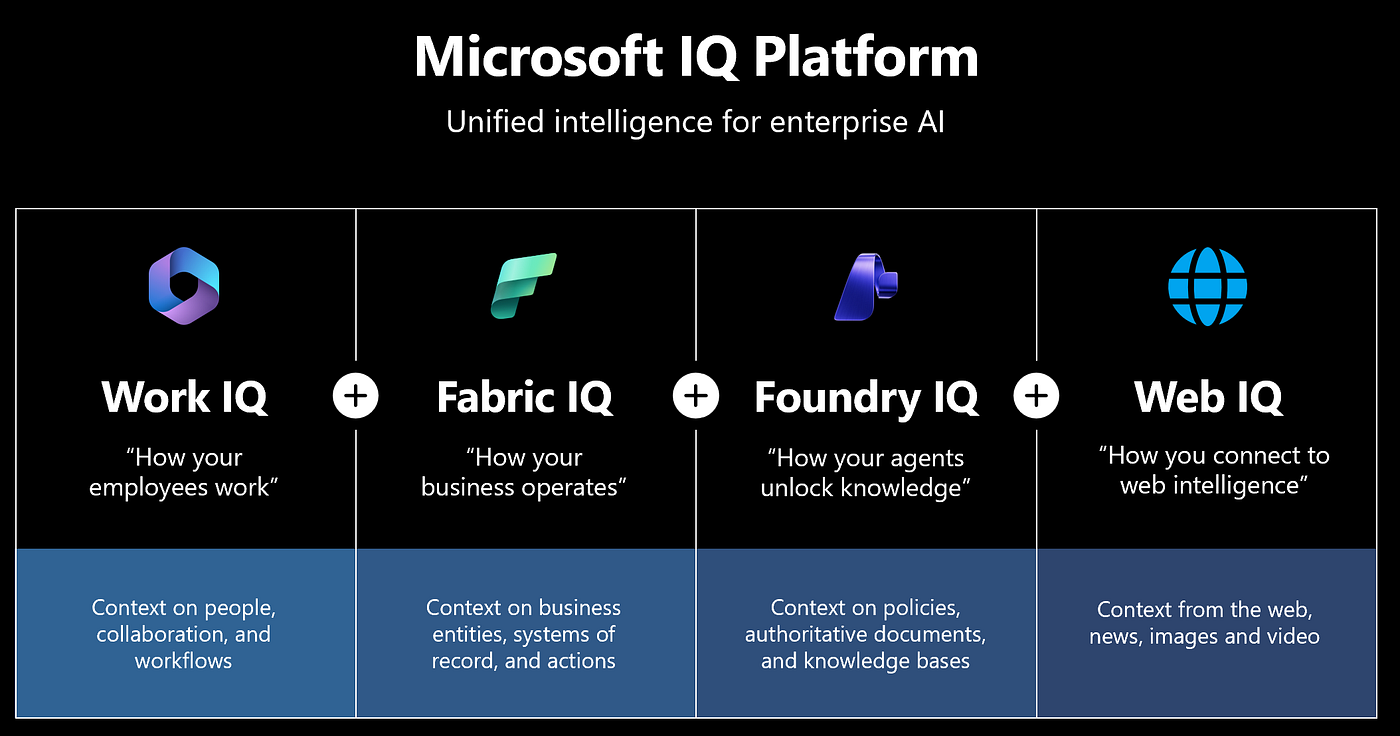
As organizations continue adopting generative AI and AI agents, one of the biggest challenges is making sure those systems are grounded in accurate, current, and trusted information. Large language models are powerful, but they are limited by what they were trained on and may not always have access to the most recent or specialized information needed to answer a business question. Microsoft IQ documentation describes Microsoft IQ as a unified intelligence layer for enterprise AI, bringing together capabilities such as Work IQ, Fabric IQ, Foundry IQ, and now Web IQ.
Web IQ is the newest addition to Microsoft’s growing IQ stack. It is designed to give AI systems and agents access to fresh, real-world information from across the web, including web pages, news, images, and videos. Instead of relying only on model knowledge or static enterprise content, Web IQ helps agents discover, rank, extract, and package relevant web-based evidence so responses can be more timely, grounded, and useful.
What Web IQ Is
Read More
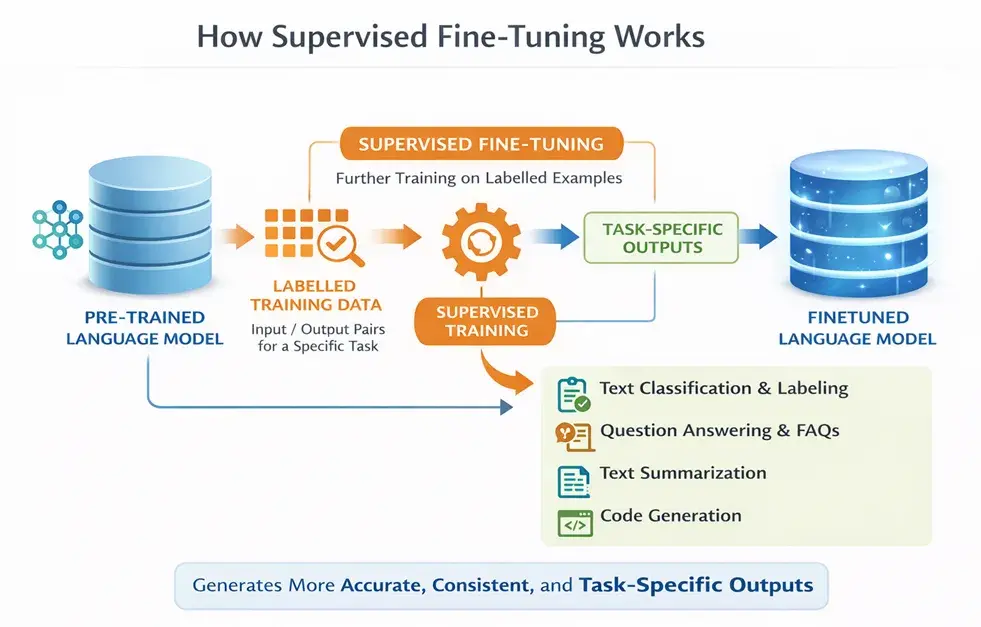

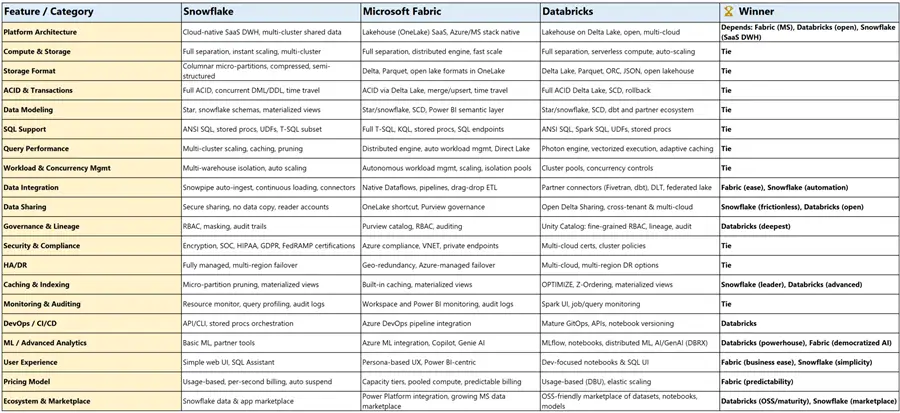
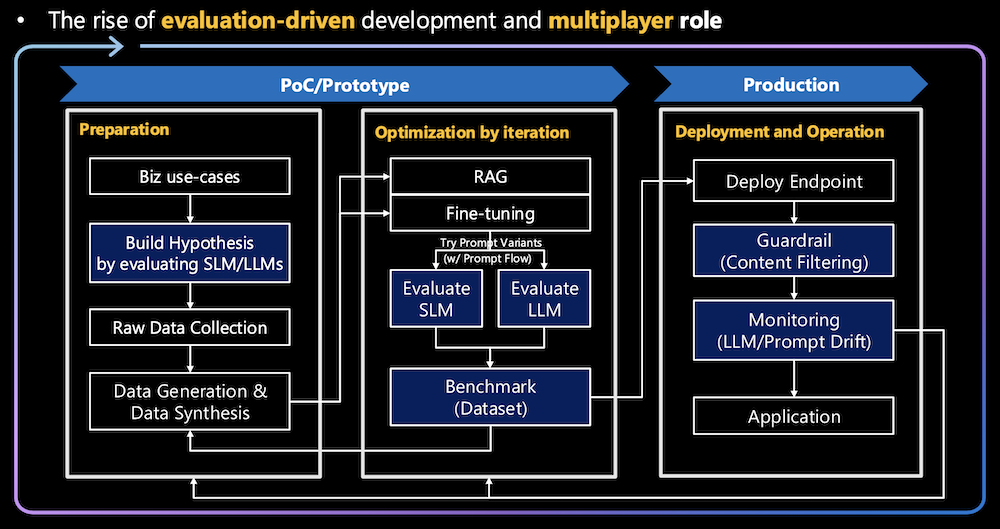
.png)